Estimating Taxon-Environment Relationships: Parametric Regressions
Parametric Regressions
Parametric regressions assume that taxon-environment relationships follow a pre-specified form. A common assumption for taxon-environment relationships is that the distribution of a particular taxon is unimodal with respect to environmental gradients. Then, in the case of presence/absence data, a convenient model for the probability of observing a particular taxon, following ter Braak and Looman (1986), is as follows (Equation 3):
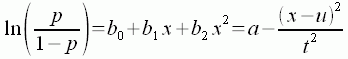 EQUATION 3
EQUATION 3
where p is the probability of observing the taxon, and the left side of the equation is the logit transformation of this probability. Additionally, x is the value of the environmental variable, u is the species optimum (the point along the environmental gradient where the probability of observing the species is maximized), t is a measure of the niche breadth, and a is related to the maximum probability of observation. The constants b0, b1, and b2 can be determined using generalized linear models (GLMs). Then the parameters u, t, and a can be determined using Equations 4, 5, and 6, respectively:
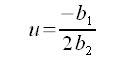 EQUATION 4 EQUATION 4 |
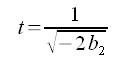 EQUATION 5 EQUATION 5 |
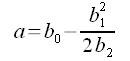 EQUATION 6 EQUATION 6 |
|---|
Examples of taxon-environment relationships estimated using Equation 3 for two genera, Heterlimnius and Malenka, with respect to stream temperature are shown in Figure 5. The computed curves closely track the observed capture probabilities for both genera. Confidence limits broaden for Heterlimnius as temperatures approach the minimum value, because data are sparse in that region.
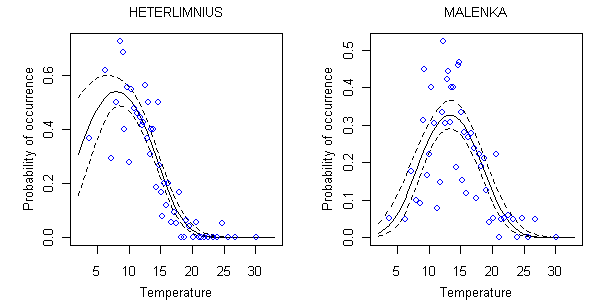 Figure 5. Relationship between probability of occurrence and temperature for Heterlimnius and Malenka using a parametric model. Solid line is mean relationship between probability of occurrence and temperature (°C). Dotted lines are estimated 90% confidence limits about the location of the regression curve. Each open circle represents the average occurrence probability in approximately 20 samples surrounding the indicated temperature.Regression models can use multiple environmental variables to predict taxon occurrences (e.g., Equation 7).
Figure 5. Relationship between probability of occurrence and temperature for Heterlimnius and Malenka using a parametric model. Solid line is mean relationship between probability of occurrence and temperature (°C). Dotted lines are estimated 90% confidence limits about the location of the regression curve. Each open circle represents the average occurrence probability in approximately 20 samples surrounding the indicated temperature.Regression models can use multiple environmental variables to predict taxon occurrences (e.g., Equation 7).
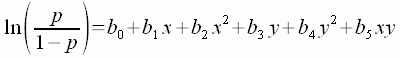 EQUATION 7
EQUATION 7
The effect of each environmental variable (e.g, x, y) on taxon occurrence is modeled as a quadratic function. Also, the possibility that the two variables interact can be modeled. In the case of Equation 7, the interaction between the two variables is modeled as the product of x and y. Terms can be included or excluded depending upon our understanding of the variables and their effects upon taxon persistence. For example, you might choose to omit the interaction term, xy, if you knew that the two environmental variables did not interact.
Simultaneously modeling several variables often provides a more accurate means of distinguishing between the effects of different correlated stressors, for example, between temperature and sands and fines as shown in Figure 6a (Yuan 2007b).
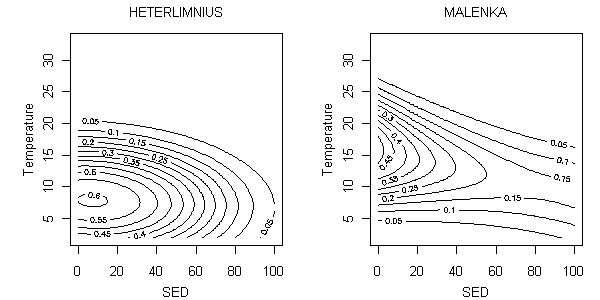 Figure 6a. Parametric relationship between probability of occurrence and temperature (°C) and percent sand/fines (SED) for Heterlimnius and Malenka using a parametric model. Contours represent mean probabilities of occurrence.
Figure 6a. Parametric relationship between probability of occurrence and temperature (°C) and percent sand/fines (SED) for Heterlimnius and Malenka using a parametric model. Contours represent mean probabilities of occurrence.
The use of parametric functions to describe the taxon-environment relationship is both a strength and a weakness of the parametric approach. On the one hand, these functions allow the investigator to summarize the taxon-environment relationship using a short list of pre-defined parameters. On the other hand, the a priori assumption of a functional form may restrict the taxon-environment relationship to a shape that is not well supported by field observations. Plots of observed data and modeled functional fits can be inspected to help establish whether the assumed functional forms are appropriate. Statistical scripts for computing single variable parametric regressions are available under the R scripts tab of this section.
Once taxon-environment relationships have been estimated using parametric regression, the most appropriate method to use for computing inferences is a maximum likelihood approach.
Abundance Data
Taxon-environment relationships based on absolute or relative abundance data also can be modeled, but the regression models for doing this become more complex. The use of presence/absence data, rather than abundance data, is recommended in most cases.
The abundance of a given taxon can be difficult to model statistically because the abundance values vary strongly from no individuals to hundreds, or thousands of individuals. Because of this variance, and because abundance values are strictly positive, the distribution of the sampling error for abundance observations are often assumed negative binomial (White and Bennets 1996).
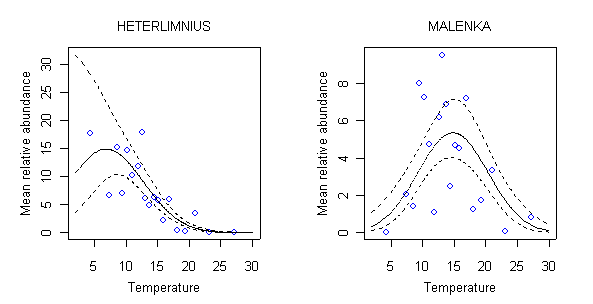 Figure 6b. Relationship between relative abundance and temperature for Heterlimnius and Malenka. Solid line is mean relationship determined between abundance and temperature determined by a negative binomial regression. Dotted lines are estimated 90% confidence limits about the location of the mean relationship. Open circles represent average relative abundance in approximately 10 samples surrounding the indicated temperature.
Figure 6b. Relationship between relative abundance and temperature for Heterlimnius and Malenka. Solid line is mean relationship determined between abundance and temperature determined by a negative binomial regression. Dotted lines are estimated 90% confidence limits about the location of the mean relationship. Open circles represent average relative abundance in approximately 10 samples surrounding the indicated temperature.
References
- ter Braak CJF, Looman CWN (1986) Weighted averaging, logistic regression and the gaussian response model. Plant Ecology 65:3-11.
- White GC, Bennets RE (1996) Analysis of frequency count data using the negative binomial distribution. Ecology 77:2549-2557.
- Yuan LL (2007) Using biological assemblage composition to infer the values of covarying environmental factors. Freshwater Biology 52:1159-1175.